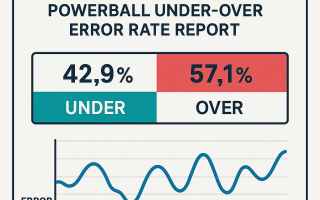
파워볼 언더-오버 오차율 리포트
페이지 정보

본문

파워볼류 이진 결과 스트림을 분석할 때 가장 먼저 해야 할 일은 목표를 날카롭게 정의하고 전제를 문서로 고정하는 일이며, 본 가이드는 언더 대 오버의 실측 분포가 이론적 기준(기본 50:50)에서 얼마나 어긋나는지 정량화하고 그 편차의 통계적 유의성과 시간에 따른 드리프트를 함께 평가하도록 설계되어 있으며, 타이 또는 무효 상태가 있는 플랫폼이라면 해당 관측을 제외하거나 별도 집계한 뒤 유효 표본을 다시 산출하는 절차를 필수 규칙으로 설정하여 해석의 혼선을 막아야 합니다.
분석 전 과정에서 관측 편향과 표본 부족과 다중검정 착시를 일관되게 경계하는 태도를 내재화해야 하며, 데이터 수집 기간과 장치 변경, 버전 릴리스 등 외생적 변동점을 타임라인으로 정리하여 추정치의 급격한 이동이 시스템 이벤트와 동시 발생했는지 여부를 항상 대조하도록 습관화하는 것이 좋고, 여기서 제시하는 틀은 실데이터가 아직 없어도 바로 붙여 넣어 사용할 수 있는 표준 템플릿·검정 절차·시각화 레이아웃·자동화 코드 골격을 통합 제공함으로써 “데이터만 채우면 곧바로 리포트”라는 작업 흐름을 지향합니다.
규정 준수와 책임 있는 데이터 사용 원칙은 기술적 선택보다 우선하며, 여러분의 지역 법률과 이용 중인 플랫폼 약관을 항상 먼저 검토하고, 합법적이고 투명한 목적의 품질 모니터링·리스크 관리·시스템 검증 용도로만 결과를 활용해야 하며, 분석 로그와 설정값과 버전을 꾸준히 남겨 재현성과 감사를 보장하는 관리 체계를 표준화해야 합니다.
시간대는 예시로 아시아/마닐라 표준시를 사용하지만 어떤 표준시를 쓰든 ts 컬럼에 타임존 정보를 명확히 표기하는 규칙만 지키면 비교 가능성이 유지되며, 집계 기준 시점과 윈도우 정의(예: 일 경계, 고정 폭/가변 폭 등)를 문서와 코드에서 일치시킴으로써 재처리와 교차검증을 크게 단순화할 수 있습니다.
이론 기준이 50:50이 아닐 수 있다는 점도 고려하여, 예컨대 타이가 일정 비율로 발생해 유효 표본의 母확률이 달라지거나 규칙상 오버의 사전 확률이 다르게 알려져 있다면 p0를 해당 값으로 바꾸어 전체 절차를 그대로 실행할 수 있도록 모든 수식은 일반화된 형태로 제시하며, 이는 서로 다른 룰셋을 쓰는 플랫폼 간 비교에도 유연하게 적용됩니다.
효과크기가 매우 작을 때 통계 유의성이 나와도 실무적 의미는 미약할 수 있으므로, 추정치의 신뢰구간과 표본 규모, 그룹 간 일관성, 데이터 수집 변동점을 함께 읽는 “맥락 기반 해석”을 권고하며, 이런 원칙을 리포트 상단 요약과 해석 섹션에 반복해서 주지시켜 과잉 확신을 방지합니다.
본 문서의 핵심 산출물은 운영팀과 분석팀이 같은 지면에서 의사결정을 공유하도록 구성된 실행형 리포트이며, 특히 경보 임계·롤링 윈도우·다중검정 보정 방식이 코드와 문서에서 동일하게 정의되도록 템플릿을 제공함으로써 “사후 재현 가능성”과 “타 팀 이식성”을 동시에 확보합니다.
끝으로 브랜드나 게임 유형에 상관없이 적용 가능한 일반 원칙을 채택하되, 로컬 룰과 배당 구조를 반영한 p0·타이 처리·그룹 축 선정만 커스터마이즈하면 즉시 현장에 투입 가능한 수준의 품질 지침과 자동화 흐름을 제공하는 것이 목표이며, 이때 파워볼 언더-오버 오차율 리포트라는 용어는 본 템플릿으로 생성되는 산출물을 명확히 지칭하는 공식 명명으로 사용합니다.
데이터 준비 템플릿
분석을 바로 시작할 수 있도록 최소 컬럼 집합과 선택 컬럼을 아래와 같이 정의하며, CSV·구글 시트·데이터 웨어하우스 어느 환경에서도 동일 스키마를 맞추면 코드가 그대로 작동하고 리포트 템플릿도 자동으로 채워질 수 있도록 설계했습니다.
필수 컬럼은 draw_id(회차 표식), ts(타임스탬프, 타임존 명시), over_flag(이진 결과: 오버=1/언더=0) 세 가지이며, 선택 컬럼으로 sum_value(합계값), threshold(기준값), pred_p_over(사전 예측 확률), group_key(그룹 식별자: 시간대/요일/플랫폼/테이블 등)를 권장하고, 복수 그룹 축이 필요하면 group_key1, group_key2처럼 차원을 늘리면 피벗과 교차분석이 자연스럽습니다.
타임스탬프 ts는 연-월-일 시:분:초와 타임존을 반드시 포함하며, 가능한 한 원시 수집 표준시를 변환 없이 저장하고 보고 단계에서만 로컬 시간으로 바꾸는 방식을 추천하는데, 이는 재처리·감사 추적·다지역 비교에서 발생하는 혼선을 크게 줄여줍니다.
누락과 이상치에 대비하여 over_flag는 0/1만 허용하고 그 외 입력은 결측 처리하며, sum_value와 threshold는 숫자형으로 강제 파싱, draw_id는 중복을 허용하되 ts와 병합하여 유일 키를 구성하면 중복 수집 탐지가 쉬워지고, ETL에서는 “미래 시각 금지·역전 정렬 금지·타임존 누락 금지” 같은 유효성 규칙을 사전에 선언해 파이프라인 안정성을 높입니다.
샘플 5행을 아래와 같이 제공하면 판다스/시트 함수만으로도 지표를 계산할 수 있으며, group_key를 “요일-시간대” 같은 규칙적 문자열로 정의하면 피벗·도수분포·시간대 비교를 손쉽게 만들 수 있고, 동일 데이터로 다차원 교차분석을 돌리려면 조인 전략을 단순화하기 위해 날짜 파생 컬럼(예: date, hour, dow)을 미리 생성해 두는 것도 좋습니다.
데이터 용량이 커질 경우 파티셔닝 전략(예: 날짜/플랫폼 단위)을 채택해 증분 로딩과 배치 시간을 단축하고, 누락/중복/비정상 분포를 탐지하는 “수집 위생 대시보드”를 별도로 운영하면 본 분석 모듈로 들어오기 전 단계에서 문제를 조기 차단할 수 있어 다운스트림 품질을 안정적으로 유지할 수 있습니다.
다음 샘플은 마닐라 시간 기준의 기본 스키마를 보여주며, 입력 파일의 인코딩(UTF-8)과 필드 구분자(쉼표), 날짜 포맷(ISO 8601)을 표준화하여 협업과 도구 간 호환성을 극대화합니다.
데이터 보존 정책 측면에서는 최소 180일(권장 365일)의 원본 보관과 집계본(요약 테이블) 동시 유지, 그리고 스키마 버전 태깅을 의무화하여 장기 추세 비교와 회귀 분석을 위한 자료 기반을 확보해 두어야 합니다.
컬럼 타입 필수 설명 예시
draw_id 문자열 예 회차 식별자 또는 키 조합 20250811-2005
ts 날짜시간 예 타임존 포함 또는 별도 명시 2025-08-11 20:05
over_flag 정수(0/1) 예 오버=1, 언더=0 이진 결과 1
sum_value 수치 선택 언오버 판단에 쓰인 합 812
threshold 수치 선택 기준값(고정이면 동일) 810
pred_p_over 실수(0~1) 선택 사전 예측 확률 0.54
group_key 문자열 선택 시간대/요일/테이블/플랫폼 등 Mon-20h
핵심 KPI 정의와 계산식
기본 가정은 타이가 없거나 타이를 분석 대상에서 제외했다는 전제이며, 타이가 존재한다면 유효 표본을 N_eff로 두고 p0 기준도 타이 제외 확률로 조정하여 계산하는 편이 일관되며, 이때 표본 수(N)는 유효 행 수, 오버 실측 비율 p̂는 over_flag의 평균으로 계산하고 절대 편차 AbsDiff = |p̂ - p0|와 상대 오차율 RelError = |p̂ - p0| / p0를 함께 보고하면 해석이 직관적입니다.
효과크기를 보강하려면 위험 차이(Risk Difference)는 AbsDiff와 동일하게 제시하고, 오즈비(Odds Ratio)는 (p̂/(1-p̂)) / (p0/(1-p0))로 정의하여 1을 기준으로 해석하며, 필요 시 아크사인 변환 효과크기(Cohen’s h = 2·arcsin√p̂ − 2·arcsin√p0)를 병기하면 큰 표본에서 미세 차이를 비교하는 데 유용합니다.
신뢰구간은 작은 표본이나 p가 0.5에서 멀어지는 상황을 고려해 윌슨 구간을 기본으로 추천하며, z=1.96일 때 분모 1 + z²/N, 중심 p̂ + z²/(2N), 반경 z·√(p̂(1−p̂)/N + z²/(4N²))를 사용하여 하한·상한을 산출하고, 극단 비율 또는 아주 작은 N에서는 클로퍼–피어슨(정확) 구간을 보조로 제시해 안정성을 확보합니다.
유의성 검정은 귀무가설 H0: p = p0 대비 이항 검정을 사용하며, 양측 검정을 기본으로 하되 분명한 사전 가정이 있을 때만 단측을 고려하고, 보고서에는 원시 p값과 보정 p값(FDR) 중 의사결정 기준을 명시하여 거짓 양성률을 통제합니다.
다중 그룹 동시 검정 시 FDR(Benjamini–Hochberg)을 기본으로 적용하고, 본페로니처럼 보수적인 방법은 차선책으로 남겨두되, 샘플 규모가 지나치게 작은 그룹은 자동 회색 처리와 “해석 보류” 주석을 달아 과잉 해석을 예방합니다.
요약 수식은 다음과 같으며 p0 ≠ 0.5인 경우에도 그대로 치환해 사용합니다: N = 유효행수, p̂ = mean(over_flag), AbsDiff = |p̂ − p0|, RelError = |p̂ − p0|/p0, WilsonCI = [(centre−rad)/den, (centre+rad)/den], p-value = BinomialTest(sum(over_flag), N, p0, two-sided).
롤링 추정치의 표준오차는 SE_roll = √(p̂_roll(1−p̂_roll)/W)(W=창 길이)로 근사하여 밴드를 그릴 수 있으며, 이는 일상 변동폭을 시각화하는 데 유용하고, 임계선 교차가 잦을 때는 경보 히스테리시스를 설계해 경보 피로를 줄입니다.
운영 관점에서 이 섹션의 결과는 파워볼 언더-오버 오차율 리포트 상단 요약 카드에 그대로 들어가며, “표본수, p̂, AbsDiff, RelError, Wilson 95% CI, 이항 p값, 판단(채택/기각)”의 순서로 고정 포맷을 사용하면 의사결정 속도를 높일 수 있습니다.
신뢰구간과 유의성: 고급 주제
작은 표본 또는 극단 비율 환경에서는 클로퍼–피어슨 구간과 함께 중간 p(mid-p) 보정의 효과를 비교 제시하면 과도한 보수성으로 인해 유의성이 과소 추정되는 문제를 완화할 근거를 제공할 수 있으며, 반대로 큰 표본에서 정규 근사 구간은 빠르고 실용적인 대안이지만 보고서 본문에는 윌슨 값을 기본으로 싣는 것을 권합니다.
아그레스티–쿠올(Agresti–Coull) 구간은 p̃ = (x + z²/2)/(N + z²)로 스무딩 후 정규 근사를 적용하는 실전형 방법으로 구현이 간단하고 성능이 양호하여 보조 지표로 유용하며, 서로 다른 구간이 비슷한 범위를 내는지 비교하면 표본 위생과 모델 적합성 점검에 도움이 됩니다.
다중검정 보정은 FDR 외에도 BY(Benjamini–Yekutieli) 같은 상관 견디는 변형을 검토할 수 있고, 운영 대시보드에서는 “원시 p값/보정 p값/보정 임계(예: q<0.05)”를 나란히 표기하고, 필터로 최소 N 기준과 최소 효과크기 기준을 동시에 걸어 해석의 견실함을 보장해야 합니다.
베이지안 관점이 필요한 팀은 베타 사전–사후를 써서 크레딧 구간(예: 95% HDI)과 “|p−p0| > δ” 확률을 보고하는 규칙을 정의할 수 있으며, 작은 표본이나 불안정한 기간에도 안정된 추정을 제공하고 사전정보(예: 최근 분기 평균)를 자연스럽게 반영할 수 있다는 장점이 있습니다.
효과크기 보고는 단순 유의성보다 중요하므로 위험 차이, 오즈비, 로그 오즈비의 신뢰구간을 함께 제시하고, 운영 변경 또는 장치 교체 전후 비교에서는 절대 차이(percentage point)와 상대 변화율(%)을 분리해 해석하면 커뮤니케이션이 명료해집니다.
추가적으로 전력 분석(power analysis)을 통해 “현재 표본으로 탐지 가능한 최소 효과크기(MDE)”를 산출해 리포트에 포함하면, 결과가 비유의여도 데이터가 충분했는지, 아니면 더 모아야 하는지 의사결정에 큰 도움을 줍니다.
분석 반복 시 동일 데이터로 다수의 가설 테스트를 수행하지 않도록 “사전등록(analysis plan pre-registration)”을 내규화하고, 대시보드 상에서는 테스트 카운터와 최근 30일 내 수행된 검정 수를 표시해 p-해킹 가능성을 조직적으로 낮추는 것도 권장됩니다.
이 모든 절차의 목적은 “유의성의 착시를 줄이고 효과크기에 초점 맞추기”이며, 팀 내부 리뷰 체크리스트로 “구간 포함 여부, 효과크기 크기, N, 외생 이벤트 일치, 보정 적용 여부”를 상단 카드로 요약하면 재현성과 품질이 한 단계 상승합니다.
예측모델 품질 지표 확장
pred_p_over가 제공되는 경우 단순 정확도 외에 브라이어 점수(Brier Score), 로그 손실(Log Loss), 캘리브레이션 지표(ECE/MCE), 캘리브레이션 회귀(Intercept/Slope), 신뢰 다이어그램(리라이어빌리티 다이어그램)을 병기해야 하며, 브라이어 점수는 평균제곱오차로 정의되어 값이 낮을수록 좋고 확률예측의 품질을 직관적으로 비교할 수 있습니다.
버킷 캘리브레이션 절대오차는 예측확률을 K개 구간으로 나누고, 각 버킷 내 실측 비율과 평균 예측확률의 차이의 절대값을 가중평균하여 산출하며, 히스토그램(예측 분포)과 신뢰구간을 겹쳐 보여주면 과신/과소신 구간을 한눈에 파악할 수 있고, 필요 시 플랫 베이스라 (pred_p_over=0.5) 대비 브라이어 상대 개선율을 보고하면 모델 도입 효과를 금액·위험 관점으로 번역하기 쉬워집니다.
브라이어 디컴포지션을 통해 분산(uncertainty), 해명가능성(resolution), 불가약 오류(reliability) 성분을 분해하면 “왜 점수가 좋아졌는가”를 해석할 수 있고, 그룹별 캘리브레이션(시간대/요일/플랫폼/테이블/장치)과 예측–실측 잔차를 병렬로 제시하면 체계적 편향을 조기에 포착할 수 있습니다.
모델 비교 시 AUC 같은 임계값 무관 지표는 클래스 균형이 50:50에 가까운 환경에서는 덜 유용할 수 있으므로, 확률 품질 중심의 지표군(브라이어, 로그 손실, ECE)을 우선하고, 임계값 의존 지표(정확도/정밀도/재현율)는 운영 정책에 맞춰 “특정 손익 목적” 하에서 부수적으로 평가하는 것을 권합니다.
캘리브레이션 개선은 플랫/플랫+이소토닉/플랫+플랫스케일링(Platt scaling) 후보를 교차검증으로 비교하고, 시간 드리프트 환경에서는 “온라인 재캘리브레이션”(예: 슬라이딩 윈도우 적합)을 적용하면 장기 안정성이 높아지며, 이때 보정된 확률은 별도 컬럼(p_over_cal)로 저장해 원본 대비 개선 효과를 추적합니다.
운영 현장에서는 작은 수치 개선도 대량 트래픽 누적 효과가 커질 수 있으므로, “1bp 개선 × 일일 트래픽 × 기간” 형태의 누적 기대 개선치를 리포트에 포함해 투자 대비 효과를 명시하고, 경영층을 위한 TL;DR 카드에 해당 수치를 노출하면 예산과 리소스 의사결정이 쉬워집니다.
모델 품질 지표는 본 분석의 핵심 KPI와 같은 지면에 요약 카드로 배치하되, 캘리브레이션 진단 플롯은 전용 섹션으로 분리하여 과밀 정보를 피하고, 각 지표의 정의·방향성·해석 팁을 캡션에 포함해 오독을 최소화합니다.
마지막으로, 모델이 게임 룰이나 배당과 무관한 “확률 추정”만 담당한다는 점을 강조해 규정 준수 리스크를 줄이고, 훈련–적용 분리, 드리프트 경보, 재학습 기준선 등 MLOps 모범사례를 병행합니다.
드리프트와 안정성 모니터링
시간에 따른 변화를 감지하려면 롤링 윈도우 비율, 누적합(CUSUM), 페이지–힌클리(Page–Hinkley), 변경점 탐지(BoCPD/Pruned Exact Linear Time 등)를 함께 쓰면 민감도와 특이도의 균형을 잡을 수 있으며, 롤링은 예를 들어 200회 단위 평균을 만들어 기준선 p0 대비 위·아래 편차를 시각화하고, “극값 범위”를 보고하면 일상 변동폭의 직관적 상한·하한을 설정하는 데 도움이 됩니다.
CUSUM은 각 회차에서 (over_flag − p0)를 누적하여 장기 편차가 위 또는 아래로 쌓이는지 보여주고, 관리도 관점의 상·하 경계선을 설정해 조기 경고 지표로 사용할 수 있으며, 페이지–힌클리는 평균이 갑자기 이동하는 구간을 포착하는 데 유리해 운영 변경, 장치 교체, 규칙 수정 시점을 자동으로 표시하는 데 적합합니다.
베이지안 온라인 변경점 탐지는 구간 전환의 사후 확률을 시계열 온라인 방식으로 계산하여 노이즈가 큰 데이터에서도 과도한 경보를 줄일 수 있고, 운영팀에 실시간 알림을 보내는 자동화 파이프라인과 결합하면 최소 인력으로 안정적인 감시 체계를 구축할 수 있으며, 경보에는 히스테리시스·백오프 정책을 적용해 경보 피로를 방지해야 합니다.
트렌드 검정이 필요하면 만–킨달(Mann–Kendall)로 단조 증가/감소 경향을 추정하고, 자기상관이 의심되면 런 검정과 류앙–박스(Ljung–Box)로 독립성 가정을 점검한 뒤 결과 해석의 보수성을 높여야 하며, 변화가 없는 정상 시스템에서도 자연 변동의 뭉침이 드물지 않다는 “클러스터 착시” 사실을 팀 교육 자료에 포함시키는 것이 유익합니다.
실시간 감시에서는 윈도우 크기와 경보 민감도 사이의 트레이드오프가 핵심이므로, 대시보드에서 W(창 길이) 슬라이더·q(보정 임계) 선택·경보 쿨다운 설정을 노출해 협업자가 스스로 튜닝할 수 있게 만들면 운영 효율이 크게 향상됩니다.
드리프트 경보의 사후 처리 절차(SOP)를 명문화해 “경보→로그 대조→원인 가설→검증→완화 조치→회귀 테스트→종결” 단계를 체크리스트화하고, 경보의 정/오 탐지율을 월간 점검해 임계와 알고리즘을 지속적으로 개선해야 하며, 경보 설명성(왜 울렸는가)을 메타데이터로 기록해 회고의 품질을 높입니다.
이 섹션의 시각화 결과는 리포트에서 1) 롤링 비율 라인, 2) CUSUM 라인, 3) 변경점 마커로 3단 그리드에 배치하면 한눈에 흐름과 급변 지점을 파악할 수 있으며, “평상시 범위 vs 이상 구간”을 배경 음영으로 구분하면 독자의 지각 부담을 줄일 수 있습니다.
운영 대시보드의 드리프트 탭은 파워볼 언더-오버 오차율 리포트의 핵심 부분으로, 단순 스냅샷을 넘어 “변화의 추적”을 제도화하여 시스템 안정성 문화의 근간을 이룹니다.
군집 연속성 지표와 무작위열 비교
연속 길이(run length) 분포를 구해 k 이상 스트릭의 출현 빈도를 측정하고, 무작위 이항열에서 기대되는 분포와 비교하면 눈으로 보이는 드라마틱한 뭉침이 실제로 이상 신호인지 자연 변동인지 구분하는 데 도움이 되며, 특히 k≥3 연속이 얼마나 자주 나오는지와 지그재그 구간 비율(부호가 번갈아 바뀌는 구간)을 함께 보여주면 체감과 수치의 간극을 줄일 수 있습니다.
월드–울포위츠(Wald–Wolfowitz) 런 검정은 부호 열의 런 수를 기반으로 독립성 여부를 판단하므로 전처리가 간단하고 빠르게 적용 가능하며, 1차 마르코프 체인 적합을 통해 전이 확률이 (언더→오버, 오버→언더)에서 0.5와 유의하게 다른지 검사하면 구조적 편향 가설에 대한 스크리닝이 가능합니다.
이상 스트릭이 관측되더라도 다중검정 상황이라면 거짓 양성의 위험이 커지므로 FDR 보정을 기본 적용하고, 관측된 이상이 운영 변경·특정 거래량 급증·타임존 이동 등 외생 변수와 시간적으로 일치하는지 로그와 대조하는 습관을 갖추어야 하며, 필요 시 부트스트랩을 통해 스트릭 지표의 신뢰구간을 함께 제시합니다.
시각화는 누적 막대(연속 길이별 카운트), 기대분포 라인(이항 모델 기반), 초과/결핍 음영으로 구성하면 이해가 빠르고, 툴팁에는 “실제 횟수, 기대 횟수, p값, FDR 보정 p”를 노출해 해석을 안내합니다.
데이터 밀도가 낮은 구간에서는 스트릭 기반 지표의 분산이 커지므로 최소 표본 기준을 강제하고, 회색 처리와 함께 “추가 수집 권고” 라벨을 부착하여 리포트의 신뢰성을 유지하는 것이 중요하며, 동일한 구간을 중복 보고하지 않도록 구간 분할 규칙을 고정합니다.
런 기반 지표는 사람의 직관과 맞닿아 커뮤니케이션에 유리하지만, “보이는 패턴=원인”이라는 착각을 유발하기 쉬우므로 반드시 검정 결과와 함께 제시하고, 운영 이벤트와의 교차 타임라인을 제공하여 책임 있는 해석을 유도해야 합니다.
마지막으로, 무작위열 비교 섹션에는 시뮬레이션 기반의 기준선(예: 10만 회 몬테카를로) 요약을 제공하면 직관적 검증이 가능하며, 시뮬레이션에서는 난수 시드·실험 설정을 고정해 재현성을 확보합니다.
이러한 군집·연속성 진단은 요약 KPI의 맹점을 보완하여 “분포는 비슷하지만 배치가 이상한” 경우를 밝혀내는 데 효과적입니다.
리포트 구성 템플릿
요약 섹션에는 표본수, 오버 비율 p̂, 상대 오차율 RelError, 윌슨 신뢰구간, 이항 검정 p값을 한 줄 카드로 채우고, 유의수준 0.05 기준에서 “기각/채택” 판단 문구를 자동 생성하여 가독성을 높이며, 작은 표본 경고와 최소 효과크기(MDE)도 함께 표시합니다.
세부 결과에서는 전체 언더/오버 건수, AbsDiff와 RelError를 반복 표기하여 본문과 표 사이의 참조를 쉽게 하고, 롤링 200회 극값 범위를 함께 보고해 일상 변동폭의 감을 바로잡게 하며, 기준선(p0)과 “신뢰 밴드”를 같은 축에 표시해 오독을 줄입니다.
그룹 비교 섹션에서는 시간대·요일·플랫폼·테이블 등 주요 차원을 피벗 표로 전개하고 각 행마다 p̂, 오차율, p값, FDR 보정 p, 윌슨 CI를 넣고, 작은 표본 그룹은 자동 회색 처리와 “해석 보류” 도트 라벨을 붙여 과잉 해석을 막는 시각적 안전장치를 둡니다.
연속성 섹션에서는 오버 연속 k 이상 출현 빈도와 기대치의 차이를 보고하고 지그재그 구간 비율을 병기하며, 예측 모델이 있다면 정확도/브라이어/캘리브레이션 진단을 함께 요약해 모델 품질의 전반을 한 페이지에서 파악하게 하고, 캡션에는 지표 정의와 방향성을 간단히 명시합니다.
해석 섹션에서는 신뢰구간 중복, 효과크기, 표본 규모를 함께 고려하자는 원칙을 재강조하고, 관측 편향과 수집 결측, 버전 변경 시점 점검 목록을 제공하여 읽는 이가 자기 데이터에 즉시 적용할 수 있게 하며, 법·약관 준수 주의 문구를 반복해서 표기합니다.
권고 섹션에서는 표본 확대, 층화 추정, 자동 모니터링 대시보드 운영을 제안하고, 다음 수집 주기에 반영해야 할 데이터 품질 항목(타임존 명시, 중복 제거, 타이 처리 명세)을 체크리스트로 제공해 실행을 돕습니다.
산출물 배포는 HTML/PDF 동시 출력과 이미지 아티팩트(rolling_over_rate.png, cusum.png)를 묶어 저장하고, 버전 태그와 p0, ROLL, ALPHA 등 핵심 설정을 리포트 메타에 포함하여 감사 추적이 가능하도록 설계합니다.
이 템플릿으로 생성되는 산출물은 파워볼 언더-오버 오차율 리포트라는 이름으로 고정하여 팀 간 커뮤니케이션의 표준 레퍼런스를 만들고, 변경 이력과 릴리스 노트를 아카이브에 함께 저장합니다.
엑셀·스프레드시트 즉시 계산
over_flag가 C열 2행부터라면 =AVERAGE(C2:Cn)으로 p̂를 계산하고, =ABS(AVERAGE(C2:Cn)-$P$0)로 AbsDiff, =ABS(AVERAGE(C2:Cn)-$P$0)/$P$0로 RelError를 산출할 수 있으며, 윌슨 구간은 사용자 정의 이름과 수식 조합 또는 파워쿼리 사용자 함수로 구현해 재사용성을 높입니다.
피벗 테이블에서 시간대·요일을 행으로 두고 over_flag 평균과 개수를 값으로 배치하면 그룹별 p̂와 N을 동시에 얻을 수 있고, 슬라이서로 기간을 바꿔보며 드리프트를 눈으로 점검할 수 있으며, 조건부 서식으로 RelError가 임계(예: 5%)를 넘으면 강조되도록 설정하면 실무 가독성이 향상됩니다.
롤링 200회 평균은 =AVERAGE(OFFSET(C2,ROW(C2:Cn)-ROW(C2)-199,0,200,1))처럼 OFFSET/INDEX를 조합해 창을 만들거나, 최신 엑셀의 동적 배열 기능을 활용하면 한 번의 수식으로 전체 열을 채워 그리드 계산을 빠르게 수행할 수 있고, 군집 집계는 보조열로 연속 길이를 누적하여 구현할 수 있습니다.
구글 시트에서는 QUERY, LET, MAP, LAMBDA(또는 Apps Script)로 동일 결과를 얻을 수 있으며, Apps Script 예약 실행으로 야간 배치 보고서를 자동 내보내기 하면 반복 작업을 최소화할 수 있고, Google BigQuery와 연결해 대용량 데이터도 스트리밍으로 직접 피벗할 수 있습니다.
시트 공유 시 “뷰 전용 + 필터 보기” 모드를 기본으로 하고, 원시 데이터와 계산 시트를 분리해 우발적 편집을 방지하며, 시트 상단에 “버전/작성일/데이터 범위/기준 p0”를 기재한 표준 머리말을 추가해 배포 표준을 통일합니다.
엑셀/시트 환경에서도 다중검정 보정은 간단한 수식으로 구현 가능하며, =RANK(p값)/m * q 형태로 BH 보정을 근사하는 방식(정렬 주의)을 매뉴얼화하고, 실제 리포트에는 원시/보정 값을 함께 표시하도록 합니다.
시각화는 스파크라인으로 요약 추세를, 차트에서는 기준선/신뢰밴드/경보 마커를 동시에 표시해 “읽는 즉시 판단”을 유도하고, 차트 색상은 적녹색약 안전 팔레트를 기본으로 채택합니다.
최종 출력물은 PDF로 내보내되, 데이터 링크를 깨지지 않게 하려면 “복사본 시트→PDF” 방식을 택하고, 메타 정보가 포함된 커버 페이지를 덧붙여 아카이브에 저장합니다.
파이썬 원클릭 분석 스크립트
아래 코드는 파일 이름만 바꿔 실행하면 전체 요약, 그룹별 표, 롤링·CUSUM 시각화를 한 번에 만들어 주며, FDR 보정과 윌슨 구간이 기본 포함되어 실전 리포트로 바로 붙여 넣을 수 있도록 출력 포맷을 정리했습니다. 추가로 브라이어 점수·ECE 계산과 캘리브레이션 플롯까지 생성해 모델 품질 섹션도 자동 채웁니다.
자동화 파이프라인 제안
작은 팀은 크론+파이썬 스크립트만으로도 일일 리포트를 자동 생성할 수 있고, 규모가 커지면 Airflow/Prefect/Dagster 같은 오케스트레이터로 수집–정제–검정–시각화–배포 단계를 분리하고, 재시도·경보·메트릭 수집을 체계화하여 운영 안정성을 높일 수 있습니다.
폴더 구조는 data/, src/, notebooks/, report_artifacts/, tests/, configs/로 분리하고, 환경 설정은 단일 YAML로 p0, ROLL, 그룹 축 목록, 경보 임계, 최소 N 등을 관리해 변경 비용을 낮추며, 컨테이너 이미지로 빌드해 실행 환경 차이를 제거합니다.
경보는 CUSUM 경계 초과 또는 윌슨 구간이 기준선 p0를 벗어날 때만 Slack/Email로 발송하고, 동일 이슈가 연속되는 경우 백오프 정책으로 재경보를 억제해 경보 피로를 줄이며, 경보 메타에는 “데이터 범위, p̂, AbsDiff, CI, 링크”를 포함해 원클릭 점검이 가능하도록 합니다.
CI/CD 파이프라인에서 데이터 샘플 테스트와 단위 테스트(윌슨 CI 모듈, FDR 보정, 시각화 생성)를 돌리고, 아티팩트 저장소에 결과 이미지를 업로드하며, 리포트와 설정 스냅샷을 함께 버전 관리합니다.
보안·거버넌스 측면에서는 개인정보·민감정보가 포함되지 않도록 스키마 설계를 보수적으로 하고, 외부 배포물에는 집계 지표만 담아 규정 위반 리스크를 차단합니다.
또한 장애 복구를 위해 데이터 원본의 증분 스냅샷과 로그 보관 정책을 시행하고, 장애 시 “마지막 성공 실행”에서 재시작하는 체크포인트 설계를 권장합니다.
대시보드 자동화는 Static HTML + 이미지 아티팩트로 간단히 시작할 수 있고, 점진적으로 시계열–필터–툴팁을 갖춘 BI 도구 연동으로 진화시키며, 이행 중에는 지표 정의 문서(데이터 딕셔너리)를 항상 최신으로 유지합니다.
이 모든 자동화는 리소스를 절약하고 품질을 균일화하여, 팀이 해석과 의사결정에 더 많은 시간을 쓸 수 있게 만듭니다.
품질 관리와 검증
수집 데이터의 위생을 확보하려면 유효성 검사를 자동화해야 하며, 예를 들어 over_flag가 0/1 외 값을 갖지 않는지, ts가 미래 시간을 가리키지 않는지, draw_id의 결측과 중복 비율이 허용 한계를 넘지 않는지 등의 규칙을 선언적으로 정의하고, 실패 시 차단하는 “게이트”를 파이프라인 초입에 배치해야 합니다.
Great Expectations 같은 데이터 검증 프레임워크를 사용하면 기대 규칙을 코드가 아닌 설정으로 관리할 수 있고, 실패 시 어떤 규칙이 깨졌는지 리포트 형태로 확인할 수 있어 디버깅 시간이 줄며, 작은 프로젝트에서도 도입 대비 효과가 큽니다.
버전 관리 관점에서는 스키마 변경·코드 업데이트 시점과 리포트 결과 차이를 추적할 수 있도록 커밋 메시지에 설정 값 변경을 반드시 포함시키고, 데이터 사양 문서화와 릴리스 노트를 병행하여 지식이 개인에게 갇히지 않도록 해야 합니다.
정상성 점검으로 요일·시간대별 분포가 과거와 유사한지, 타이/무효 비율이 급변하지 않는지, 결측 패턴이 특정 장치나 기간에 편중되지 않는지 등을 주기적으로 검토합니다.
로그 수준에서는 “데이터 수집기 버전, API 응답 코드, 변환 성공/실패 수, 드롭된 레코드 사유”를 별도 테이블로 축적해 시스템 건강 상태를 객관적으로 모니터링합니다.
샘플링 검토를 위한 무작위 표본 추출과 수작업 크로스체크(소수) 절차를 운영하여 자동 검증이 놓칠 수 있는 맥락 오류를 보완합니다.
품질 지표(KPI) 자체도 모니터링 대상이므로, 리포트 생성 실패·지표 계산 실패·이상치 폭증 등 메타 경보를 병행하여 “리포트의 리포트”를 만드는 것이 바람직합니다.
결과적으로, 품질 관리 계층은 신뢰 가능한 분석의 전제조건이며, 운영 신뢰를 구축하는 지름길입니다.
해석 가이드라인과 주의점
신뢰구간이 기준 확률 p0를 포함하면 관측 편차가 표본오차로 설명될 가능성이 크고, 포함하지 않더라도 AbsDiff가 아주 작다면 실무적으로 무시 가능한 차이일 수 있으므로, 유의성 여부를 이분법으로만 판단하지 말고 효과크기와 반복 측정의 일관성과 변화 시점의 외생 요인을 함께 검토해야 합니다.
롤링 곡선이 장기적으로 기준선 주변에서 되돌림을 보인다면 정상적 무작위 변동에 가깝다고 해석할 수 있고, 특정 구간의 기울기 변화가 운영 변경과 같은 로그 이벤트와 일치하는지 대조하면 원인 추정의 신뢰도를 높일 수 있으며, 이러한 대조는 리포트에 “이벤트 타임라인”으로 시각화하는 것이 좋습니다.
그룹을 많이 비교했다면 반드시 다중검정 보정을 적용하고, 유의로 표시된 그룹은 표본수와 관측 창 길이를 다시 확인해 과소 표본에서 오는 과대 해석을 경계하며, 결과를 본 뒤 지표 정의를 바꾸는 사후 가설 유도(p-해킹)는 장기 신뢰를 해치는 행위이므로 금지 규칙으로 명문화해야 합니다.
분석 결과를 게임 공략으로 오해하지 않도록, 이 리포트는 품질 모니터링과 준법·리스크 관리 목적의 통계 보고서임을 명시하고, 이론상 장기적으로는 “하우스엣지”가 결과 기대값을 지배한다는 사실을 해설하여 단기 변동에 과신하지 않도록 교육해야 하며, 참고로 블랙잭 같은 게임에서의 하우스엣지는 전략·룰에 따라 달라지지만 여전히 장기 기대값을 규정한다는 점을 비교 사례로 제시하면 맥락 이해에 도움이 됩니다.
관측 편향을 줄이려면 수집 장치·앱 버전·지역·네트워크 조건에 따른 차이를 층화하고, 플랫폼 간 비교 시에는 동일 기간·동일 룰·동일 타이 처리 기준으로 맞춘 뒤 FDR 보정된 p값과 효과크기를 함께 보고해야 공정한 비교가 됩니다.
모델이 개입된 시스템이라면 업데이트·캘리브레이션 변경 시점에 “전·후” 구간을 분명히 나누고, 사후 선택 바이어스를 피하기 위해 구간 경계를 사전에 정의해 두는 것이 안전하며, 작은 편차라도 운영상 큰 영향이 있을 수 있으므로 임계값은 도메인 팀과 합의한 정책 문서로 고정합니다.
결론을 내릴 때는 “데이터의 한계와 가정”을 별도 상자에 요약하고, 잠재 혼란변수(confounder) 목록과 향후 수집 개선안을 함께 제시해 독자가 해석의 범위를 이해하도록 돕습니다.
마지막으로, 해석 문구는 중립적이고 검증 가능해야 하며, 과장된 표현이나 성급한 일반화를 피하고, 대체 설명 가설을 최소 하나 이상 검토한 뒤 결론을 제시하는 습관을 권합니다.
리치 스니펫 요약 표
아래 표는 주요 섹션별 핵심 한 줄과 실행 위치를 요약해 검색·대시보드·문서 탐색에서 유용한 미니 색인 역할을 수행합니다.
섹션 핵심 한 줄 실행 위치
데이터 스키마 필수 3컬럼 + 타임존 명시로 재현성 확보 수집 시스템
KPI p̂·AbsDiff·RelError·Wilson CI를 기본 세트로 보고 분석 모듈
검정 이항 검정 + FDR 보정으로 거짓 양성 억제 통계 모듈
드리프트 롤링·CUSUM·변경점 탐지로 조기 경보 모니터링
모델 브라이어·캘리브레이션으로 확률 품질 평가 모델 평가
시각화 기준선·신뢰대 표기로 오독 최소화 리포트
자동화 크론/오케스트레이터로 일일 보고 파이프라인
품질 사전 검증·실패 시 차단으로 위생 유지 검증 계층
해석 유의성보다 효과크기·일관성에 주목 의사결정
준수 법·약관·책임 원칙 우선 거버넌스
자주 묻는 질문(FAQ)
Q. 표본이 몇 회 이상이면 믿을 만한가요?
A. 이상적 표본은 수천 회 이상이며, 오차 한계 ±2% 수준으로 줄이는 데만도 약 2,500회 이상이 권장되고, 이보다 작은 표본에서는 신뢰구간이 넓어 작은 편차에 과잉 반응하기 쉬우므로 해석을 보수적으로 하시기 바랍니다.
Q. 기준 확률이 50%가 아니라면 어떻게 하나요?
A. 타이 비중이나 룰이 알려져 있다면 p0를 그 값으로 바꾸고 전 계산을 동일하게 수행하면 되며, 리포트의 기준선과 주석도 같은 값으로 변경해 해석 혼동을 줄이는 것이 중요합니다.
Q. 그룹이 많아지면 무엇을 조심해야 하나요?
A. 다중검정 보정이 필수이며 작은 표본 그룹에서 유의가 나오면 먼저 표본수 경고와 함께 회색 처리로 과잉 해석을 막고, 다음 수집 주기에 해당 그룹 표본을 확장해 재검증하시길 권합니다.
Q. 모델의 브라이어 점수가 낮아졌는데 정확도는 비슷합니다.
A. 확률예측 품질은 개선되었으나 결정 임계값을 바꾸지 않아 정확도가 정체된 경우로, 캘리브레이션 플롯과 기대 수익 관점의 임계값 최적화를 병행하면 개선을 체감할 수 있습니다.
Q. 롤링 그래프가 자주 기준선을 넘나듭니다.
A. 정상적인 무작위 변동일 가능성이 높으며, 지속적 추세 확인을 위해 CUSUM과 변경점 탐지를 병행하고, 경보는 일정 기간의 편차 누적이 임계를 넘을 때만 발생하도록 설계하는 것이 좋습니다.
Q. 데이터가 비공개라 팀 외 공유가 어렵습니다.
A. 이 가이드는 데이터 없이도 실행되는 더미 템플릿과 코드 골격을 제공하므로 구조와 절차는 외부 공유가 가능하고, 사내 공유는 민감 정보를 제거한 지표 요약본을 사용하는 방식을 추천합니다.
Q. 엑셀만으로 가능한가요?
A. 가능합니다. 다만 반복 작업·보정·변경점 탐지 같은 자동화는 파이썬/R이 훨씬 효율적이므로, 엑셀은 확인·일회성 분석에, 코드 기반은 정기 리포트에 배분하는 하이브리드 운영을 권합니다.
Q. 표본이 커질수록 AbsDiff가 작아지나요?
A. 실제 편차가 0이면 분산 감소로 보이는 편차가 줄어드는 경향이 있지만, 미세한 편향이 존재한다면 표본이 커질수록 그 편차가 더 선명해질 수 있으니 신뢰구간과 효과크기를 함께 보아야 합니다.
Q. 잦은 경보로 팀이 피로합니다.
A. 경보 정책에 히스테리시스를 부여하고 동일 원인의 반복 경보를 묶어주며, 임계값을 롤링 표준편차 기반 동적 임계로 전환하면 과도한 경보를 줄일 수 있습니다.
Q. 리포트 템플릿을 커스터마이즈할 수 있나요?
A. 가능합니다. 그룹 축 추가, 지표 확장, 시각화 테마·로고 교체는 상단 설정만 수정해도 쉽게 반영되도록 설계되어 있고, 기준 확률과 윈도우 길이 같은 핵심 파라미터는 설정 파일로 분리해 관리합니다.
#온라인카지노#스포츠토토#바카라명언 #바카라사이트주소 #파워볼사이트 #카지노슬롯머신전략 #카지노게임 #바카라사이트추천 #카지노사이트주소 #온라인카지노가이드 #카지노게임추천 #캄보디아카지노 #카지노게임종류 #온라인슬롯머신가이드 #바카라성공 #텍사스홀덤사이트 #슬롯머신확률 #마닐라카지노순위 #바카라금액조절 #룰렛베팅테이블 #바카라배팅포지션
분석 전 과정에서 관측 편향과 표본 부족과 다중검정 착시를 일관되게 경계하는 태도를 내재화해야 하며, 데이터 수집 기간과 장치 변경, 버전 릴리스 등 외생적 변동점을 타임라인으로 정리하여 추정치의 급격한 이동이 시스템 이벤트와 동시 발생했는지 여부를 항상 대조하도록 습관화하는 것이 좋고, 여기서 제시하는 틀은 실데이터가 아직 없어도 바로 붙여 넣어 사용할 수 있는 표준 템플릿·검정 절차·시각화 레이아웃·자동화 코드 골격을 통합 제공함으로써 “데이터만 채우면 곧바로 리포트”라는 작업 흐름을 지향합니다.
규정 준수와 책임 있는 데이터 사용 원칙은 기술적 선택보다 우선하며, 여러분의 지역 법률과 이용 중인 플랫폼 약관을 항상 먼저 검토하고, 합법적이고 투명한 목적의 품질 모니터링·리스크 관리·시스템 검증 용도로만 결과를 활용해야 하며, 분석 로그와 설정값과 버전을 꾸준히 남겨 재현성과 감사를 보장하는 관리 체계를 표준화해야 합니다.
시간대는 예시로 아시아/마닐라 표준시를 사용하지만 어떤 표준시를 쓰든 ts 컬럼에 타임존 정보를 명확히 표기하는 규칙만 지키면 비교 가능성이 유지되며, 집계 기준 시점과 윈도우 정의(예: 일 경계, 고정 폭/가변 폭 등)를 문서와 코드에서 일치시킴으로써 재처리와 교차검증을 크게 단순화할 수 있습니다.
이론 기준이 50:50이 아닐 수 있다는 점도 고려하여, 예컨대 타이가 일정 비율로 발생해 유효 표본의 母확률이 달라지거나 규칙상 오버의 사전 확률이 다르게 알려져 있다면 p0를 해당 값으로 바꾸어 전체 절차를 그대로 실행할 수 있도록 모든 수식은 일반화된 형태로 제시하며, 이는 서로 다른 룰셋을 쓰는 플랫폼 간 비교에도 유연하게 적용됩니다.
효과크기가 매우 작을 때 통계 유의성이 나와도 실무적 의미는 미약할 수 있으므로, 추정치의 신뢰구간과 표본 규모, 그룹 간 일관성, 데이터 수집 변동점을 함께 읽는 “맥락 기반 해석”을 권고하며, 이런 원칙을 리포트 상단 요약과 해석 섹션에 반복해서 주지시켜 과잉 확신을 방지합니다.
본 문서의 핵심 산출물은 운영팀과 분석팀이 같은 지면에서 의사결정을 공유하도록 구성된 실행형 리포트이며, 특히 경보 임계·롤링 윈도우·다중검정 보정 방식이 코드와 문서에서 동일하게 정의되도록 템플릿을 제공함으로써 “사후 재현 가능성”과 “타 팀 이식성”을 동시에 확보합니다.
끝으로 브랜드나 게임 유형에 상관없이 적용 가능한 일반 원칙을 채택하되, 로컬 룰과 배당 구조를 반영한 p0·타이 처리·그룹 축 선정만 커스터마이즈하면 즉시 현장에 투입 가능한 수준의 품질 지침과 자동화 흐름을 제공하는 것이 목표이며, 이때 파워볼 언더-오버 오차율 리포트라는 용어는 본 템플릿으로 생성되는 산출물을 명확히 지칭하는 공식 명명으로 사용합니다.
데이터 준비 템플릿
분석을 바로 시작할 수 있도록 최소 컬럼 집합과 선택 컬럼을 아래와 같이 정의하며, CSV·구글 시트·데이터 웨어하우스 어느 환경에서도 동일 스키마를 맞추면 코드가 그대로 작동하고 리포트 템플릿도 자동으로 채워질 수 있도록 설계했습니다.
필수 컬럼은 draw_id(회차 표식), ts(타임스탬프, 타임존 명시), over_flag(이진 결과: 오버=1/언더=0) 세 가지이며, 선택 컬럼으로 sum_value(합계값), threshold(기준값), pred_p_over(사전 예측 확률), group_key(그룹 식별자: 시간대/요일/플랫폼/테이블 등)를 권장하고, 복수 그룹 축이 필요하면 group_key1, group_key2처럼 차원을 늘리면 피벗과 교차분석이 자연스럽습니다.
타임스탬프 ts는 연-월-일 시:분:초와 타임존을 반드시 포함하며, 가능한 한 원시 수집 표준시를 변환 없이 저장하고 보고 단계에서만 로컬 시간으로 바꾸는 방식을 추천하는데, 이는 재처리·감사 추적·다지역 비교에서 발생하는 혼선을 크게 줄여줍니다.
누락과 이상치에 대비하여 over_flag는 0/1만 허용하고 그 외 입력은 결측 처리하며, sum_value와 threshold는 숫자형으로 강제 파싱, draw_id는 중복을 허용하되 ts와 병합하여 유일 키를 구성하면 중복 수집 탐지가 쉬워지고, ETL에서는 “미래 시각 금지·역전 정렬 금지·타임존 누락 금지” 같은 유효성 규칙을 사전에 선언해 파이프라인 안정성을 높입니다.
샘플 5행을 아래와 같이 제공하면 판다스/시트 함수만으로도 지표를 계산할 수 있으며, group_key를 “요일-시간대” 같은 규칙적 문자열로 정의하면 피벗·도수분포·시간대 비교를 손쉽게 만들 수 있고, 동일 데이터로 다차원 교차분석을 돌리려면 조인 전략을 단순화하기 위해 날짜 파생 컬럼(예: date, hour, dow)을 미리 생성해 두는 것도 좋습니다.
데이터 용량이 커질 경우 파티셔닝 전략(예: 날짜/플랫폼 단위)을 채택해 증분 로딩과 배치 시간을 단축하고, 누락/중복/비정상 분포를 탐지하는 “수집 위생 대시보드”를 별도로 운영하면 본 분석 모듈로 들어오기 전 단계에서 문제를 조기 차단할 수 있어 다운스트림 품질을 안정적으로 유지할 수 있습니다.
다음 샘플은 마닐라 시간 기준의 기본 스키마를 보여주며, 입력 파일의 인코딩(UTF-8)과 필드 구분자(쉼표), 날짜 포맷(ISO 8601)을 표준화하여 협업과 도구 간 호환성을 극대화합니다.
데이터 보존 정책 측면에서는 최소 180일(권장 365일)의 원본 보관과 집계본(요약 테이블) 동시 유지, 그리고 스키마 버전 태깅을 의무화하여 장기 추세 비교와 회귀 분석을 위한 자료 기반을 확보해 두어야 합니다.
컬럼 타입 필수 설명 예시
draw_id 문자열 예 회차 식별자 또는 키 조합 20250811-2005
ts 날짜시간 예 타임존 포함 또는 별도 명시 2025-08-11 20:05
over_flag 정수(0/1) 예 오버=1, 언더=0 이진 결과 1
sum_value 수치 선택 언오버 판단에 쓰인 합 812
threshold 수치 선택 기준값(고정이면 동일) 810
pred_p_over 실수(0~1) 선택 사전 예측 확률 0.54
group_key 문자열 선택 시간대/요일/테이블/플랫폼 등 Mon-20h
핵심 KPI 정의와 계산식
기본 가정은 타이가 없거나 타이를 분석 대상에서 제외했다는 전제이며, 타이가 존재한다면 유효 표본을 N_eff로 두고 p0 기준도 타이 제외 확률로 조정하여 계산하는 편이 일관되며, 이때 표본 수(N)는 유효 행 수, 오버 실측 비율 p̂는 over_flag의 평균으로 계산하고 절대 편차 AbsDiff = |p̂ - p0|와 상대 오차율 RelError = |p̂ - p0| / p0를 함께 보고하면 해석이 직관적입니다.
효과크기를 보강하려면 위험 차이(Risk Difference)는 AbsDiff와 동일하게 제시하고, 오즈비(Odds Ratio)는 (p̂/(1-p̂)) / (p0/(1-p0))로 정의하여 1을 기준으로 해석하며, 필요 시 아크사인 변환 효과크기(Cohen’s h = 2·arcsin√p̂ − 2·arcsin√p0)를 병기하면 큰 표본에서 미세 차이를 비교하는 데 유용합니다.
신뢰구간은 작은 표본이나 p가 0.5에서 멀어지는 상황을 고려해 윌슨 구간을 기본으로 추천하며, z=1.96일 때 분모 1 + z²/N, 중심 p̂ + z²/(2N), 반경 z·√(p̂(1−p̂)/N + z²/(4N²))를 사용하여 하한·상한을 산출하고, 극단 비율 또는 아주 작은 N에서는 클로퍼–피어슨(정확) 구간을 보조로 제시해 안정성을 확보합니다.
유의성 검정은 귀무가설 H0: p = p0 대비 이항 검정을 사용하며, 양측 검정을 기본으로 하되 분명한 사전 가정이 있을 때만 단측을 고려하고, 보고서에는 원시 p값과 보정 p값(FDR) 중 의사결정 기준을 명시하여 거짓 양성률을 통제합니다.
다중 그룹 동시 검정 시 FDR(Benjamini–Hochberg)을 기본으로 적용하고, 본페로니처럼 보수적인 방법은 차선책으로 남겨두되, 샘플 규모가 지나치게 작은 그룹은 자동 회색 처리와 “해석 보류” 주석을 달아 과잉 해석을 예방합니다.
요약 수식은 다음과 같으며 p0 ≠ 0.5인 경우에도 그대로 치환해 사용합니다: N = 유효행수, p̂ = mean(over_flag), AbsDiff = |p̂ − p0|, RelError = |p̂ − p0|/p0, WilsonCI = [(centre−rad)/den, (centre+rad)/den], p-value = BinomialTest(sum(over_flag), N, p0, two-sided).
롤링 추정치의 표준오차는 SE_roll = √(p̂_roll(1−p̂_roll)/W)(W=창 길이)로 근사하여 밴드를 그릴 수 있으며, 이는 일상 변동폭을 시각화하는 데 유용하고, 임계선 교차가 잦을 때는 경보 히스테리시스를 설계해 경보 피로를 줄입니다.
운영 관점에서 이 섹션의 결과는 파워볼 언더-오버 오차율 리포트 상단 요약 카드에 그대로 들어가며, “표본수, p̂, AbsDiff, RelError, Wilson 95% CI, 이항 p값, 판단(채택/기각)”의 순서로 고정 포맷을 사용하면 의사결정 속도를 높일 수 있습니다.
신뢰구간과 유의성: 고급 주제
작은 표본 또는 극단 비율 환경에서는 클로퍼–피어슨 구간과 함께 중간 p(mid-p) 보정의 효과를 비교 제시하면 과도한 보수성으로 인해 유의성이 과소 추정되는 문제를 완화할 근거를 제공할 수 있으며, 반대로 큰 표본에서 정규 근사 구간은 빠르고 실용적인 대안이지만 보고서 본문에는 윌슨 값을 기본으로 싣는 것을 권합니다.
아그레스티–쿠올(Agresti–Coull) 구간은 p̃ = (x + z²/2)/(N + z²)로 스무딩 후 정규 근사를 적용하는 실전형 방법으로 구현이 간단하고 성능이 양호하여 보조 지표로 유용하며, 서로 다른 구간이 비슷한 범위를 내는지 비교하면 표본 위생과 모델 적합성 점검에 도움이 됩니다.
다중검정 보정은 FDR 외에도 BY(Benjamini–Yekutieli) 같은 상관 견디는 변형을 검토할 수 있고, 운영 대시보드에서는 “원시 p값/보정 p값/보정 임계(예: q<0.05)”를 나란히 표기하고, 필터로 최소 N 기준과 최소 효과크기 기준을 동시에 걸어 해석의 견실함을 보장해야 합니다.
베이지안 관점이 필요한 팀은 베타 사전–사후를 써서 크레딧 구간(예: 95% HDI)과 “|p−p0| > δ” 확률을 보고하는 규칙을 정의할 수 있으며, 작은 표본이나 불안정한 기간에도 안정된 추정을 제공하고 사전정보(예: 최근 분기 평균)를 자연스럽게 반영할 수 있다는 장점이 있습니다.
효과크기 보고는 단순 유의성보다 중요하므로 위험 차이, 오즈비, 로그 오즈비의 신뢰구간을 함께 제시하고, 운영 변경 또는 장치 교체 전후 비교에서는 절대 차이(percentage point)와 상대 변화율(%)을 분리해 해석하면 커뮤니케이션이 명료해집니다.
추가적으로 전력 분석(power analysis)을 통해 “현재 표본으로 탐지 가능한 최소 효과크기(MDE)”를 산출해 리포트에 포함하면, 결과가 비유의여도 데이터가 충분했는지, 아니면 더 모아야 하는지 의사결정에 큰 도움을 줍니다.
분석 반복 시 동일 데이터로 다수의 가설 테스트를 수행하지 않도록 “사전등록(analysis plan pre-registration)”을 내규화하고, 대시보드 상에서는 테스트 카운터와 최근 30일 내 수행된 검정 수를 표시해 p-해킹 가능성을 조직적으로 낮추는 것도 권장됩니다.
이 모든 절차의 목적은 “유의성의 착시를 줄이고 효과크기에 초점 맞추기”이며, 팀 내부 리뷰 체크리스트로 “구간 포함 여부, 효과크기 크기, N, 외생 이벤트 일치, 보정 적용 여부”를 상단 카드로 요약하면 재현성과 품질이 한 단계 상승합니다.
예측모델 품질 지표 확장
pred_p_over가 제공되는 경우 단순 정확도 외에 브라이어 점수(Brier Score), 로그 손실(Log Loss), 캘리브레이션 지표(ECE/MCE), 캘리브레이션 회귀(Intercept/Slope), 신뢰 다이어그램(리라이어빌리티 다이어그램)을 병기해야 하며, 브라이어 점수는 평균제곱오차로 정의되어 값이 낮을수록 좋고 확률예측의 품질을 직관적으로 비교할 수 있습니다.
버킷 캘리브레이션 절대오차는 예측확률을 K개 구간으로 나누고, 각 버킷 내 실측 비율과 평균 예측확률의 차이의 절대값을 가중평균하여 산출하며, 히스토그램(예측 분포)과 신뢰구간을 겹쳐 보여주면 과신/과소신 구간을 한눈에 파악할 수 있고, 필요 시 플랫 베이스라 (pred_p_over=0.5) 대비 브라이어 상대 개선율을 보고하면 모델 도입 효과를 금액·위험 관점으로 번역하기 쉬워집니다.
브라이어 디컴포지션을 통해 분산(uncertainty), 해명가능성(resolution), 불가약 오류(reliability) 성분을 분해하면 “왜 점수가 좋아졌는가”를 해석할 수 있고, 그룹별 캘리브레이션(시간대/요일/플랫폼/테이블/장치)과 예측–실측 잔차를 병렬로 제시하면 체계적 편향을 조기에 포착할 수 있습니다.
모델 비교 시 AUC 같은 임계값 무관 지표는 클래스 균형이 50:50에 가까운 환경에서는 덜 유용할 수 있으므로, 확률 품질 중심의 지표군(브라이어, 로그 손실, ECE)을 우선하고, 임계값 의존 지표(정확도/정밀도/재현율)는 운영 정책에 맞춰 “특정 손익 목적” 하에서 부수적으로 평가하는 것을 권합니다.
캘리브레이션 개선은 플랫/플랫+이소토닉/플랫+플랫스케일링(Platt scaling) 후보를 교차검증으로 비교하고, 시간 드리프트 환경에서는 “온라인 재캘리브레이션”(예: 슬라이딩 윈도우 적합)을 적용하면 장기 안정성이 높아지며, 이때 보정된 확률은 별도 컬럼(p_over_cal)로 저장해 원본 대비 개선 효과를 추적합니다.
운영 현장에서는 작은 수치 개선도 대량 트래픽 누적 효과가 커질 수 있으므로, “1bp 개선 × 일일 트래픽 × 기간” 형태의 누적 기대 개선치를 리포트에 포함해 투자 대비 효과를 명시하고, 경영층을 위한 TL;DR 카드에 해당 수치를 노출하면 예산과 리소스 의사결정이 쉬워집니다.
모델 품질 지표는 본 분석의 핵심 KPI와 같은 지면에 요약 카드로 배치하되, 캘리브레이션 진단 플롯은 전용 섹션으로 분리하여 과밀 정보를 피하고, 각 지표의 정의·방향성·해석 팁을 캡션에 포함해 오독을 최소화합니다.
마지막으로, 모델이 게임 룰이나 배당과 무관한 “확률 추정”만 담당한다는 점을 강조해 규정 준수 리스크를 줄이고, 훈련–적용 분리, 드리프트 경보, 재학습 기준선 등 MLOps 모범사례를 병행합니다.
드리프트와 안정성 모니터링
시간에 따른 변화를 감지하려면 롤링 윈도우 비율, 누적합(CUSUM), 페이지–힌클리(Page–Hinkley), 변경점 탐지(BoCPD/Pruned Exact Linear Time 등)를 함께 쓰면 민감도와 특이도의 균형을 잡을 수 있으며, 롤링은 예를 들어 200회 단위 평균을 만들어 기준선 p0 대비 위·아래 편차를 시각화하고, “극값 범위”를 보고하면 일상 변동폭의 직관적 상한·하한을 설정하는 데 도움이 됩니다.
CUSUM은 각 회차에서 (over_flag − p0)를 누적하여 장기 편차가 위 또는 아래로 쌓이는지 보여주고, 관리도 관점의 상·하 경계선을 설정해 조기 경고 지표로 사용할 수 있으며, 페이지–힌클리는 평균이 갑자기 이동하는 구간을 포착하는 데 유리해 운영 변경, 장치 교체, 규칙 수정 시점을 자동으로 표시하는 데 적합합니다.
베이지안 온라인 변경점 탐지는 구간 전환의 사후 확률을 시계열 온라인 방식으로 계산하여 노이즈가 큰 데이터에서도 과도한 경보를 줄일 수 있고, 운영팀에 실시간 알림을 보내는 자동화 파이프라인과 결합하면 최소 인력으로 안정적인 감시 체계를 구축할 수 있으며, 경보에는 히스테리시스·백오프 정책을 적용해 경보 피로를 방지해야 합니다.
트렌드 검정이 필요하면 만–킨달(Mann–Kendall)로 단조 증가/감소 경향을 추정하고, 자기상관이 의심되면 런 검정과 류앙–박스(Ljung–Box)로 독립성 가정을 점검한 뒤 결과 해석의 보수성을 높여야 하며, 변화가 없는 정상 시스템에서도 자연 변동의 뭉침이 드물지 않다는 “클러스터 착시” 사실을 팀 교육 자료에 포함시키는 것이 유익합니다.
실시간 감시에서는 윈도우 크기와 경보 민감도 사이의 트레이드오프가 핵심이므로, 대시보드에서 W(창 길이) 슬라이더·q(보정 임계) 선택·경보 쿨다운 설정을 노출해 협업자가 스스로 튜닝할 수 있게 만들면 운영 효율이 크게 향상됩니다.
드리프트 경보의 사후 처리 절차(SOP)를 명문화해 “경보→로그 대조→원인 가설→검증→완화 조치→회귀 테스트→종결” 단계를 체크리스트화하고, 경보의 정/오 탐지율을 월간 점검해 임계와 알고리즘을 지속적으로 개선해야 하며, 경보 설명성(왜 울렸는가)을 메타데이터로 기록해 회고의 품질을 높입니다.
이 섹션의 시각화 결과는 리포트에서 1) 롤링 비율 라인, 2) CUSUM 라인, 3) 변경점 마커로 3단 그리드에 배치하면 한눈에 흐름과 급변 지점을 파악할 수 있으며, “평상시 범위 vs 이상 구간”을 배경 음영으로 구분하면 독자의 지각 부담을 줄일 수 있습니다.
운영 대시보드의 드리프트 탭은 파워볼 언더-오버 오차율 리포트의 핵심 부분으로, 단순 스냅샷을 넘어 “변화의 추적”을 제도화하여 시스템 안정성 문화의 근간을 이룹니다.
군집 연속성 지표와 무작위열 비교
연속 길이(run length) 분포를 구해 k 이상 스트릭의 출현 빈도를 측정하고, 무작위 이항열에서 기대되는 분포와 비교하면 눈으로 보이는 드라마틱한 뭉침이 실제로 이상 신호인지 자연 변동인지 구분하는 데 도움이 되며, 특히 k≥3 연속이 얼마나 자주 나오는지와 지그재그 구간 비율(부호가 번갈아 바뀌는 구간)을 함께 보여주면 체감과 수치의 간극을 줄일 수 있습니다.
월드–울포위츠(Wald–Wolfowitz) 런 검정은 부호 열의 런 수를 기반으로 독립성 여부를 판단하므로 전처리가 간단하고 빠르게 적용 가능하며, 1차 마르코프 체인 적합을 통해 전이 확률이 (언더→오버, 오버→언더)에서 0.5와 유의하게 다른지 검사하면 구조적 편향 가설에 대한 스크리닝이 가능합니다.
이상 스트릭이 관측되더라도 다중검정 상황이라면 거짓 양성의 위험이 커지므로 FDR 보정을 기본 적용하고, 관측된 이상이 운영 변경·특정 거래량 급증·타임존 이동 등 외생 변수와 시간적으로 일치하는지 로그와 대조하는 습관을 갖추어야 하며, 필요 시 부트스트랩을 통해 스트릭 지표의 신뢰구간을 함께 제시합니다.
시각화는 누적 막대(연속 길이별 카운트), 기대분포 라인(이항 모델 기반), 초과/결핍 음영으로 구성하면 이해가 빠르고, 툴팁에는 “실제 횟수, 기대 횟수, p값, FDR 보정 p”를 노출해 해석을 안내합니다.
데이터 밀도가 낮은 구간에서는 스트릭 기반 지표의 분산이 커지므로 최소 표본 기준을 강제하고, 회색 처리와 함께 “추가 수집 권고” 라벨을 부착하여 리포트의 신뢰성을 유지하는 것이 중요하며, 동일한 구간을 중복 보고하지 않도록 구간 분할 규칙을 고정합니다.
런 기반 지표는 사람의 직관과 맞닿아 커뮤니케이션에 유리하지만, “보이는 패턴=원인”이라는 착각을 유발하기 쉬우므로 반드시 검정 결과와 함께 제시하고, 운영 이벤트와의 교차 타임라인을 제공하여 책임 있는 해석을 유도해야 합니다.
마지막으로, 무작위열 비교 섹션에는 시뮬레이션 기반의 기준선(예: 10만 회 몬테카를로) 요약을 제공하면 직관적 검증이 가능하며, 시뮬레이션에서는 난수 시드·실험 설정을 고정해 재현성을 확보합니다.
이러한 군집·연속성 진단은 요약 KPI의 맹점을 보완하여 “분포는 비슷하지만 배치가 이상한” 경우를 밝혀내는 데 효과적입니다.
리포트 구성 템플릿
요약 섹션에는 표본수, 오버 비율 p̂, 상대 오차율 RelError, 윌슨 신뢰구간, 이항 검정 p값을 한 줄 카드로 채우고, 유의수준 0.05 기준에서 “기각/채택” 판단 문구를 자동 생성하여 가독성을 높이며, 작은 표본 경고와 최소 효과크기(MDE)도 함께 표시합니다.
세부 결과에서는 전체 언더/오버 건수, AbsDiff와 RelError를 반복 표기하여 본문과 표 사이의 참조를 쉽게 하고, 롤링 200회 극값 범위를 함께 보고해 일상 변동폭의 감을 바로잡게 하며, 기준선(p0)과 “신뢰 밴드”를 같은 축에 표시해 오독을 줄입니다.
그룹 비교 섹션에서는 시간대·요일·플랫폼·테이블 등 주요 차원을 피벗 표로 전개하고 각 행마다 p̂, 오차율, p값, FDR 보정 p, 윌슨 CI를 넣고, 작은 표본 그룹은 자동 회색 처리와 “해석 보류” 도트 라벨을 붙여 과잉 해석을 막는 시각적 안전장치를 둡니다.
연속성 섹션에서는 오버 연속 k 이상 출현 빈도와 기대치의 차이를 보고하고 지그재그 구간 비율을 병기하며, 예측 모델이 있다면 정확도/브라이어/캘리브레이션 진단을 함께 요약해 모델 품질의 전반을 한 페이지에서 파악하게 하고, 캡션에는 지표 정의와 방향성을 간단히 명시합니다.
해석 섹션에서는 신뢰구간 중복, 효과크기, 표본 규모를 함께 고려하자는 원칙을 재강조하고, 관측 편향과 수집 결측, 버전 변경 시점 점검 목록을 제공하여 읽는 이가 자기 데이터에 즉시 적용할 수 있게 하며, 법·약관 준수 주의 문구를 반복해서 표기합니다.
권고 섹션에서는 표본 확대, 층화 추정, 자동 모니터링 대시보드 운영을 제안하고, 다음 수집 주기에 반영해야 할 데이터 품질 항목(타임존 명시, 중복 제거, 타이 처리 명세)을 체크리스트로 제공해 실행을 돕습니다.
산출물 배포는 HTML/PDF 동시 출력과 이미지 아티팩트(rolling_over_rate.png, cusum.png)를 묶어 저장하고, 버전 태그와 p0, ROLL, ALPHA 등 핵심 설정을 리포트 메타에 포함하여 감사 추적이 가능하도록 설계합니다.
이 템플릿으로 생성되는 산출물은 파워볼 언더-오버 오차율 리포트라는 이름으로 고정하여 팀 간 커뮤니케이션의 표준 레퍼런스를 만들고, 변경 이력과 릴리스 노트를 아카이브에 함께 저장합니다.
엑셀·스프레드시트 즉시 계산
over_flag가 C열 2행부터라면 =AVERAGE(C2:Cn)으로 p̂를 계산하고, =ABS(AVERAGE(C2:Cn)-$P$0)로 AbsDiff, =ABS(AVERAGE(C2:Cn)-$P$0)/$P$0로 RelError를 산출할 수 있으며, 윌슨 구간은 사용자 정의 이름과 수식 조합 또는 파워쿼리 사용자 함수로 구현해 재사용성을 높입니다.
피벗 테이블에서 시간대·요일을 행으로 두고 over_flag 평균과 개수를 값으로 배치하면 그룹별 p̂와 N을 동시에 얻을 수 있고, 슬라이서로 기간을 바꿔보며 드리프트를 눈으로 점검할 수 있으며, 조건부 서식으로 RelError가 임계(예: 5%)를 넘으면 강조되도록 설정하면 실무 가독성이 향상됩니다.
롤링 200회 평균은 =AVERAGE(OFFSET(C2,ROW(C2:Cn)-ROW(C2)-199,0,200,1))처럼 OFFSET/INDEX를 조합해 창을 만들거나, 최신 엑셀의 동적 배열 기능을 활용하면 한 번의 수식으로 전체 열을 채워 그리드 계산을 빠르게 수행할 수 있고, 군집 집계는 보조열로 연속 길이를 누적하여 구현할 수 있습니다.
구글 시트에서는 QUERY, LET, MAP, LAMBDA(또는 Apps Script)로 동일 결과를 얻을 수 있으며, Apps Script 예약 실행으로 야간 배치 보고서를 자동 내보내기 하면 반복 작업을 최소화할 수 있고, Google BigQuery와 연결해 대용량 데이터도 스트리밍으로 직접 피벗할 수 있습니다.
시트 공유 시 “뷰 전용 + 필터 보기” 모드를 기본으로 하고, 원시 데이터와 계산 시트를 분리해 우발적 편집을 방지하며, 시트 상단에 “버전/작성일/데이터 범위/기준 p0”를 기재한 표준 머리말을 추가해 배포 표준을 통일합니다.
엑셀/시트 환경에서도 다중검정 보정은 간단한 수식으로 구현 가능하며, =RANK(p값)/m * q 형태로 BH 보정을 근사하는 방식(정렬 주의)을 매뉴얼화하고, 실제 리포트에는 원시/보정 값을 함께 표시하도록 합니다.
시각화는 스파크라인으로 요약 추세를, 차트에서는 기준선/신뢰밴드/경보 마커를 동시에 표시해 “읽는 즉시 판단”을 유도하고, 차트 색상은 적녹색약 안전 팔레트를 기본으로 채택합니다.
최종 출력물은 PDF로 내보내되, 데이터 링크를 깨지지 않게 하려면 “복사본 시트→PDF” 방식을 택하고, 메타 정보가 포함된 커버 페이지를 덧붙여 아카이브에 저장합니다.
파이썬 원클릭 분석 스크립트
아래 코드는 파일 이름만 바꿔 실행하면 전체 요약, 그룹별 표, 롤링·CUSUM 시각화를 한 번에 만들어 주며, FDR 보정과 윌슨 구간이 기본 포함되어 실전 리포트로 바로 붙여 넣을 수 있도록 출력 포맷을 정리했습니다. 추가로 브라이어 점수·ECE 계산과 캘리브레이션 플롯까지 생성해 모델 품질 섹션도 자동 채웁니다.
자동화 파이프라인 제안
작은 팀은 크론+파이썬 스크립트만으로도 일일 리포트를 자동 생성할 수 있고, 규모가 커지면 Airflow/Prefect/Dagster 같은 오케스트레이터로 수집–정제–검정–시각화–배포 단계를 분리하고, 재시도·경보·메트릭 수집을 체계화하여 운영 안정성을 높일 수 있습니다.
폴더 구조는 data/, src/, notebooks/, report_artifacts/, tests/, configs/로 분리하고, 환경 설정은 단일 YAML로 p0, ROLL, 그룹 축 목록, 경보 임계, 최소 N 등을 관리해 변경 비용을 낮추며, 컨테이너 이미지로 빌드해 실행 환경 차이를 제거합니다.
경보는 CUSUM 경계 초과 또는 윌슨 구간이 기준선 p0를 벗어날 때만 Slack/Email로 발송하고, 동일 이슈가 연속되는 경우 백오프 정책으로 재경보를 억제해 경보 피로를 줄이며, 경보 메타에는 “데이터 범위, p̂, AbsDiff, CI, 링크”를 포함해 원클릭 점검이 가능하도록 합니다.
CI/CD 파이프라인에서 데이터 샘플 테스트와 단위 테스트(윌슨 CI 모듈, FDR 보정, 시각화 생성)를 돌리고, 아티팩트 저장소에 결과 이미지를 업로드하며, 리포트와 설정 스냅샷을 함께 버전 관리합니다.
보안·거버넌스 측면에서는 개인정보·민감정보가 포함되지 않도록 스키마 설계를 보수적으로 하고, 외부 배포물에는 집계 지표만 담아 규정 위반 리스크를 차단합니다.
또한 장애 복구를 위해 데이터 원본의 증분 스냅샷과 로그 보관 정책을 시행하고, 장애 시 “마지막 성공 실행”에서 재시작하는 체크포인트 설계를 권장합니다.
대시보드 자동화는 Static HTML + 이미지 아티팩트로 간단히 시작할 수 있고, 점진적으로 시계열–필터–툴팁을 갖춘 BI 도구 연동으로 진화시키며, 이행 중에는 지표 정의 문서(데이터 딕셔너리)를 항상 최신으로 유지합니다.
이 모든 자동화는 리소스를 절약하고 품질을 균일화하여, 팀이 해석과 의사결정에 더 많은 시간을 쓸 수 있게 만듭니다.
품질 관리와 검증
수집 데이터의 위생을 확보하려면 유효성 검사를 자동화해야 하며, 예를 들어 over_flag가 0/1 외 값을 갖지 않는지, ts가 미래 시간을 가리키지 않는지, draw_id의 결측과 중복 비율이 허용 한계를 넘지 않는지 등의 규칙을 선언적으로 정의하고, 실패 시 차단하는 “게이트”를 파이프라인 초입에 배치해야 합니다.
Great Expectations 같은 데이터 검증 프레임워크를 사용하면 기대 규칙을 코드가 아닌 설정으로 관리할 수 있고, 실패 시 어떤 규칙이 깨졌는지 리포트 형태로 확인할 수 있어 디버깅 시간이 줄며, 작은 프로젝트에서도 도입 대비 효과가 큽니다.
버전 관리 관점에서는 스키마 변경·코드 업데이트 시점과 리포트 결과 차이를 추적할 수 있도록 커밋 메시지에 설정 값 변경을 반드시 포함시키고, 데이터 사양 문서화와 릴리스 노트를 병행하여 지식이 개인에게 갇히지 않도록 해야 합니다.
정상성 점검으로 요일·시간대별 분포가 과거와 유사한지, 타이/무효 비율이 급변하지 않는지, 결측 패턴이 특정 장치나 기간에 편중되지 않는지 등을 주기적으로 검토합니다.
로그 수준에서는 “데이터 수집기 버전, API 응답 코드, 변환 성공/실패 수, 드롭된 레코드 사유”를 별도 테이블로 축적해 시스템 건강 상태를 객관적으로 모니터링합니다.
샘플링 검토를 위한 무작위 표본 추출과 수작업 크로스체크(소수) 절차를 운영하여 자동 검증이 놓칠 수 있는 맥락 오류를 보완합니다.
품질 지표(KPI) 자체도 모니터링 대상이므로, 리포트 생성 실패·지표 계산 실패·이상치 폭증 등 메타 경보를 병행하여 “리포트의 리포트”를 만드는 것이 바람직합니다.
결과적으로, 품질 관리 계층은 신뢰 가능한 분석의 전제조건이며, 운영 신뢰를 구축하는 지름길입니다.
해석 가이드라인과 주의점
신뢰구간이 기준 확률 p0를 포함하면 관측 편차가 표본오차로 설명될 가능성이 크고, 포함하지 않더라도 AbsDiff가 아주 작다면 실무적으로 무시 가능한 차이일 수 있으므로, 유의성 여부를 이분법으로만 판단하지 말고 효과크기와 반복 측정의 일관성과 변화 시점의 외생 요인을 함께 검토해야 합니다.
롤링 곡선이 장기적으로 기준선 주변에서 되돌림을 보인다면 정상적 무작위 변동에 가깝다고 해석할 수 있고, 특정 구간의 기울기 변화가 운영 변경과 같은 로그 이벤트와 일치하는지 대조하면 원인 추정의 신뢰도를 높일 수 있으며, 이러한 대조는 리포트에 “이벤트 타임라인”으로 시각화하는 것이 좋습니다.
그룹을 많이 비교했다면 반드시 다중검정 보정을 적용하고, 유의로 표시된 그룹은 표본수와 관측 창 길이를 다시 확인해 과소 표본에서 오는 과대 해석을 경계하며, 결과를 본 뒤 지표 정의를 바꾸는 사후 가설 유도(p-해킹)는 장기 신뢰를 해치는 행위이므로 금지 규칙으로 명문화해야 합니다.
분석 결과를 게임 공략으로 오해하지 않도록, 이 리포트는 품질 모니터링과 준법·리스크 관리 목적의 통계 보고서임을 명시하고, 이론상 장기적으로는 “하우스엣지”가 결과 기대값을 지배한다는 사실을 해설하여 단기 변동에 과신하지 않도록 교육해야 하며, 참고로 블랙잭 같은 게임에서의 하우스엣지는 전략·룰에 따라 달라지지만 여전히 장기 기대값을 규정한다는 점을 비교 사례로 제시하면 맥락 이해에 도움이 됩니다.
관측 편향을 줄이려면 수집 장치·앱 버전·지역·네트워크 조건에 따른 차이를 층화하고, 플랫폼 간 비교 시에는 동일 기간·동일 룰·동일 타이 처리 기준으로 맞춘 뒤 FDR 보정된 p값과 효과크기를 함께 보고해야 공정한 비교가 됩니다.
모델이 개입된 시스템이라면 업데이트·캘리브레이션 변경 시점에 “전·후” 구간을 분명히 나누고, 사후 선택 바이어스를 피하기 위해 구간 경계를 사전에 정의해 두는 것이 안전하며, 작은 편차라도 운영상 큰 영향이 있을 수 있으므로 임계값은 도메인 팀과 합의한 정책 문서로 고정합니다.
결론을 내릴 때는 “데이터의 한계와 가정”을 별도 상자에 요약하고, 잠재 혼란변수(confounder) 목록과 향후 수집 개선안을 함께 제시해 독자가 해석의 범위를 이해하도록 돕습니다.
마지막으로, 해석 문구는 중립적이고 검증 가능해야 하며, 과장된 표현이나 성급한 일반화를 피하고, 대체 설명 가설을 최소 하나 이상 검토한 뒤 결론을 제시하는 습관을 권합니다.
리치 스니펫 요약 표
아래 표는 주요 섹션별 핵심 한 줄과 실행 위치를 요약해 검색·대시보드·문서 탐색에서 유용한 미니 색인 역할을 수행합니다.
섹션 핵심 한 줄 실행 위치
데이터 스키마 필수 3컬럼 + 타임존 명시로 재현성 확보 수집 시스템
KPI p̂·AbsDiff·RelError·Wilson CI를 기본 세트로 보고 분석 모듈
검정 이항 검정 + FDR 보정으로 거짓 양성 억제 통계 모듈
드리프트 롤링·CUSUM·변경점 탐지로 조기 경보 모니터링
모델 브라이어·캘리브레이션으로 확률 품질 평가 모델 평가
시각화 기준선·신뢰대 표기로 오독 최소화 리포트
자동화 크론/오케스트레이터로 일일 보고 파이프라인
품질 사전 검증·실패 시 차단으로 위생 유지 검증 계층
해석 유의성보다 효과크기·일관성에 주목 의사결정
준수 법·약관·책임 원칙 우선 거버넌스
자주 묻는 질문(FAQ)
Q. 표본이 몇 회 이상이면 믿을 만한가요?
A. 이상적 표본은 수천 회 이상이며, 오차 한계 ±2% 수준으로 줄이는 데만도 약 2,500회 이상이 권장되고, 이보다 작은 표본에서는 신뢰구간이 넓어 작은 편차에 과잉 반응하기 쉬우므로 해석을 보수적으로 하시기 바랍니다.
Q. 기준 확률이 50%가 아니라면 어떻게 하나요?
A. 타이 비중이나 룰이 알려져 있다면 p0를 그 값으로 바꾸고 전 계산을 동일하게 수행하면 되며, 리포트의 기준선과 주석도 같은 값으로 변경해 해석 혼동을 줄이는 것이 중요합니다.
Q. 그룹이 많아지면 무엇을 조심해야 하나요?
A. 다중검정 보정이 필수이며 작은 표본 그룹에서 유의가 나오면 먼저 표본수 경고와 함께 회색 처리로 과잉 해석을 막고, 다음 수집 주기에 해당 그룹 표본을 확장해 재검증하시길 권합니다.
Q. 모델의 브라이어 점수가 낮아졌는데 정확도는 비슷합니다.
A. 확률예측 품질은 개선되었으나 결정 임계값을 바꾸지 않아 정확도가 정체된 경우로, 캘리브레이션 플롯과 기대 수익 관점의 임계값 최적화를 병행하면 개선을 체감할 수 있습니다.
Q. 롤링 그래프가 자주 기준선을 넘나듭니다.
A. 정상적인 무작위 변동일 가능성이 높으며, 지속적 추세 확인을 위해 CUSUM과 변경점 탐지를 병행하고, 경보는 일정 기간의 편차 누적이 임계를 넘을 때만 발생하도록 설계하는 것이 좋습니다.
Q. 데이터가 비공개라 팀 외 공유가 어렵습니다.
A. 이 가이드는 데이터 없이도 실행되는 더미 템플릿과 코드 골격을 제공하므로 구조와 절차는 외부 공유가 가능하고, 사내 공유는 민감 정보를 제거한 지표 요약본을 사용하는 방식을 추천합니다.
Q. 엑셀만으로 가능한가요?
A. 가능합니다. 다만 반복 작업·보정·변경점 탐지 같은 자동화는 파이썬/R이 훨씬 효율적이므로, 엑셀은 확인·일회성 분석에, 코드 기반은 정기 리포트에 배분하는 하이브리드 운영을 권합니다.
Q. 표본이 커질수록 AbsDiff가 작아지나요?
A. 실제 편차가 0이면 분산 감소로 보이는 편차가 줄어드는 경향이 있지만, 미세한 편향이 존재한다면 표본이 커질수록 그 편차가 더 선명해질 수 있으니 신뢰구간과 효과크기를 함께 보아야 합니다.
Q. 잦은 경보로 팀이 피로합니다.
A. 경보 정책에 히스테리시스를 부여하고 동일 원인의 반복 경보를 묶어주며, 임계값을 롤링 표준편차 기반 동적 임계로 전환하면 과도한 경보를 줄일 수 있습니다.
Q. 리포트 템플릿을 커스터마이즈할 수 있나요?
A. 가능합니다. 그룹 축 추가, 지표 확장, 시각화 테마·로고 교체는 상단 설정만 수정해도 쉽게 반영되도록 설계되어 있고, 기준 확률과 윈도우 길이 같은 핵심 파라미터는 설정 파일로 분리해 관리합니다.
#온라인카지노#스포츠토토#바카라명언 #바카라사이트주소 #파워볼사이트 #카지노슬롯머신전략 #카지노게임 #바카라사이트추천 #카지노사이트주소 #온라인카지노가이드 #카지노게임추천 #캄보디아카지노 #카지노게임종류 #온라인슬롯머신가이드 #바카라성공 #텍사스홀덤사이트 #슬롯머신확률 #마닐라카지노순위 #바카라금액조절 #룰렛베팅테이블 #바카라배팅포지션
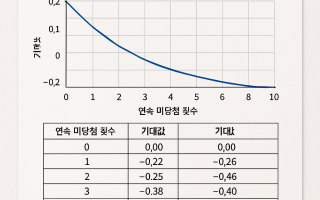
- 이전글슬롯 연속 미당첨 후 기대값 변동 분석 리포트 25.08.13
- 다음글룰렛 베팅의 타이밍을 알면 수익 흐름이 보인다 25.08.08
댓글목록
등록된 댓글이 없습니다.